Results and Conclusions
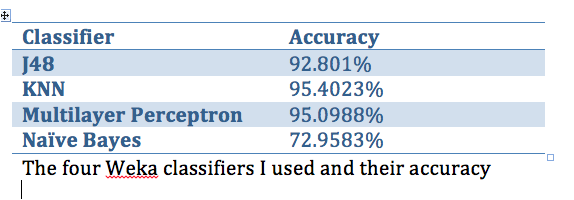
The results of my experiment showed that when cross validating with ten folds on the total data set of all the user responses, K-Nearest-Neighbor had the highest accuracy at 95.4023% followed very closely by the Multilayer Perceptron model at 95.0988%. This implies that the algorithm that the website uses probably weights the user's responses higher for some houses and lower for other houses. This makes sense considering the idea that most people have a lot of overlap between houses.
This overlap is shown in the other part of my experiment that tried to see if the model that this training set created would work when used on attributes that real characters had. For the five characters I created data for, KNN and the Multilayer Perceptron models always outputted the correct House, while J48 and Naive Bayes sometimes with the less obvious characters got confused.
The J48 model did tell me that question 1 was the best attribute to split on, however, giving the question of how you want others to perceive you the highest information gain.
This overlap is shown in the other part of my experiment that tried to see if the model that this training set created would work when used on attributes that real characters had. For the five characters I created data for, KNN and the Multilayer Perceptron models always outputted the correct House, while J48 and Naive Bayes sometimes with the less obvious characters got confused.
The J48 model did tell me that question 1 was the best attribute to split on, however, giving the question of how you want others to perceive you the highest information gain.
